不解密识别恶意流量
广告位API接口通信错误,查看德得广告获取帮助
在过去的两年中,我们一直在系统的收集和分析恶意软件生成的数据包捕获。在此期间,我们观察到,有一种恶意软件是使用基于TLS的加密来逃避检测,而这种恶意软件的样本百分比正在稳步增加。2015年8月,2.21%的恶意软件样本使用TLS,而到了2017年5月,数据增加到21.44%。在同一时间段内,使用TLS但是没有和HTTP进行未加密连接的恶意软件,从0.12%增加到4.45%。识别加密网络流量中包含的威胁会带来一系列独特的挑战。监控这些流量,使他们不受恶意软件威胁和侵害是非常重要的,这样做也是为了维护用户的隐私。由于在TLS会话时,模式匹配效果较差,因此我们需要开发一种新方法,即能够准确检测恶意软件的通信。为此,我们利用使用流的各个数据包长度,以及到达时间间隔来了解传输数据的行为特征,并使用ClientHello中包含的TLS元数据,来理解传输数据的TLS客户端。 我们将这两种视图结合在一个受监督的机器学习框架中,这样我们便能够在TLS通信中检测已知和未知的威胁。
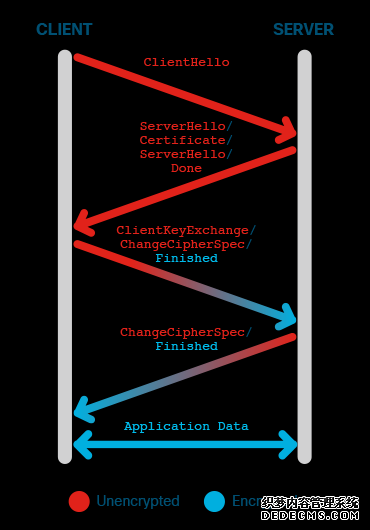
为了更直观的了解,图1提供了TLS会话的简化视图。在TLS 1.2中,大多数有趣的TLS握手消息都未加密,在图1中我们用红色标记。我们用于分类的所有TLS特定信息都来自ClientHello,它也可以在TLS 1.3中访问。
数据
在这个项目的整个生命周期中,我们一直认为数据是我们成功的核心。我们与ThreatGrid和Cisco Infosec合作,获取恶意包捕获和实时企业数据。这些数据反馈对我们的帮助是巨大的,它能够引导我们的分析,并且发展出最具信息量的流动特征。我们所分析的数据特性是十分有趣的,为了让大家理解有趣在那里,我们首先关注一个特定的恶意软件样本,bestafera,它是著名的键盘记录和数据泄露软件。
通过数据包长度和时间进行行为分析
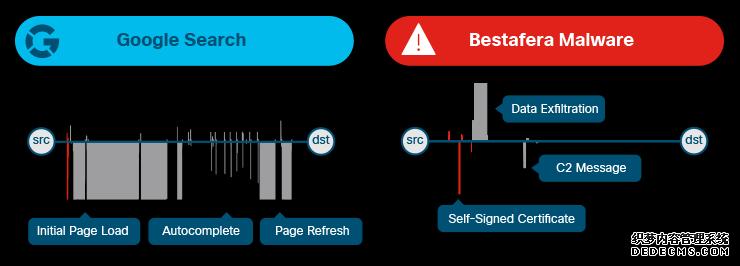
图2显示了两个不同TLS会话的数据包长度和到达间隔:图2a中的谷歌搜索和图2b中的bestafera启动连接。 x轴表示时间,向上的线表示从客户端(源)发送到服务器(目的地)的数据包大小,向下的线表示从服务器发送到客户端的数据包大小。红线表示未加密的消息,黑线是加密的应用程序数据记录的大小。
谷歌搜索遵循一种典型模式:客户端的初始请求位于一个小的出站数据包中,然后是大量响应,它跨越许多MTU大小的数据包。这几个来回的数据包是谷歌在我还在输入时,自动完成的搜索。 最后,谷歌认为它对我输入的内容有自己想法,所以发送了一组更新的结果。 bestafera与之通信的服务器首先发送一个包含自签名证书的数据包,这可以看作是图2b中第一个向下的细红线。握手后,客户端立即开始将数据泄露到服务器。然后是暂停,服务器定期发送计划命令和控制消息。针对会话内容,数据包长度和到达时间间隔无法提供更深入的见解,但它们确实有助于推断会话的行为方面。
使用TLS元数据对应用程序进行指纹识别
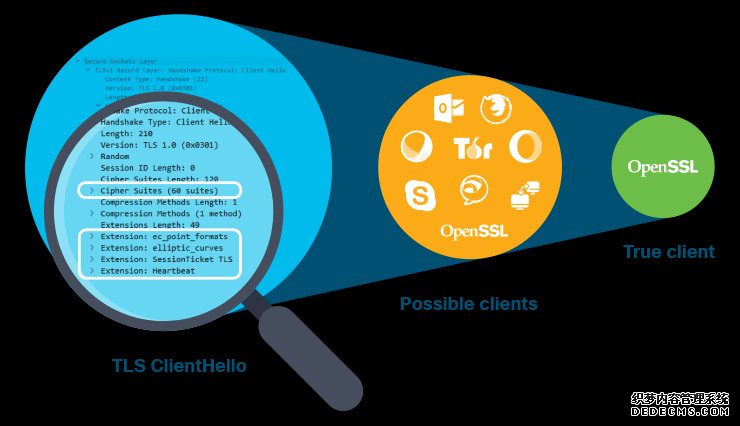
TLS ClientHello消息提供了两个特别有趣的信息,他们可以用来区分不同的TLS库和应用程序。客户端向服务器提供了一个列表,这其中包括在客户端的优先级中订购的合适密码套件的列表。每个密码套件定义了一组方法,例如加密算法和伪随机函数,这些方法将使用TLS建立连接和传输数据。客户端还可以发布一组TLS扩展,它可以向服务器提供密钥交换所需的参数,例如ec_point_formats。
在提供的唯一密码套件的数量和提供的不同子组中,密码套件提供的向量是可以变化。类似的扩展列表也会根据连接的上下文而变化。因为大多数应用程序通常有不同的优先级,所以,在实践中,这些列表可以而且确实包含大量歧视性信息。例如,桌面浏览器倾向于更重的重量,更安全的加密算法,移动应用程序倾向于更高效的加密算法。他默认的密码套件提供与TLS库捆绑的客户向量,而且他通常提供更广泛的密码套件,这样可以帮助测试服务器配置。
大多数用户级应用程序,以及在野外看到的大量TLS连接,都使用流行的TLS库,如BoringSSL,NSS或OpenSSL。这些应用程序通常具有唯一的TLS指纹,因为开发人员会修改库的默认值,这样便能优化它的应用程序。更明确地说,OpenSSL 1.0.1r中s_client的TLS指纹很可能与使用OpenSSL 1.0.1r进行通信的应用程序不同。这也是为什么bestafera的TLS指纹既有趣又独特的原因——它使用OpenSSL 1.0.1r的默认设置来创建其TLS连接。
应用机器学习
特征表示
对于本文,我们关注的是三种数据类型的简单特性:传统的NetFlow、数据包长度以及从TLS ClientHello获取的信息。这些数据类型都是从单个TLS会话中提取的,但我们还开发了包含多个流的特征模型。在训练之前,将所有特征都归一化为具有零均值和单位方差。
Legacy
我们使用了传统NetFlow中存在的5个功能:流的持续时间、从客户端发送的数据包数、从服务器发送的数据包数、从客户端发送的字节数以及从服务器发送的字节数。
SPL
我们创建一个长度为20的特征向量,其中每个条目都是双向流中相应的数据包大小。从客户端到服务器的数据包大小是正数,从服务器到客户端的数据包大小是负数。
TLS
我们分析了提供的密码套件列表,以及ClientHello消息中包含的广告扩展列表。在我们的数据中,我们观察到176个独特的密码套件和21个独特的扩展,这导致了长度为197的二进制特征向量。如果密码套件或扩展名出现在ClientHello消息中,则相应的功能设置为1。
学习
所有的结果都使用了scikit-learn随机森林实现。基于我们之前进行的纵向研究,我们将集合中树木的数量设置为125棵,并且将树的每一次分裂所考虑的特征数量设置为特征总数的平方根。随机森林模型使用的特性集由遗留特性、SPL、TLS特性的某些子集组成,具体需要看实验情况。 在过去的两年中,我们一直在系统的收集和分析恶意软件生成的数据包捕获。在此期间,我们观察到,有一种恶意软件是使用基于TLS的加密来逃避检测,而这种恶意软件的样本百分比正在稳步增加。2015年8月,2.21%的恶意软件样本使用TLS,而到了2017年5月,数据增加到21.44%。在同一时间段内,使用TLS但是没有和HTTP进行未加密连接的恶意软件,从0.12%增加到4.45%。
识别加密网络流量中包含的威胁会带来一系列独特的挑战。监控这些流量,使他们不受恶意软件威胁和侵害是非常重要的,这样做也是为了维护用户的隐私。由于在TLS会话时,模式匹配效果较差,因此我们需要开发一种新方法,即能够准确检测恶意软件的通信。为此,我们利用使用流的各个数据包长度,以及到达时间间隔来了解传输数据的行为特征,并使用ClientHello中包含的TLS元数据,来理解传输数据的TLS客户端。 我们将这两种视图结合在一个受监督的机器学习框架中,这样我们便能够在TLS通信中检测已知和未知的威胁。 内容来自无奈安全网
为了更直观的了解,图1提供了TLS会话的简化视图。在TLS 1.2中,大多数有趣的TLS握手消息都未加密,在图1中我们用红色标记。我们用于分类的所有TLS特定信息都来自ClientHello,它也可以在TLS 1.3中访问。
数据
在这个项目的整个生命周期中,我们一直认为数据是我们成功的核心。我们与ThreatGrid和Cisco Infosec合作,获取恶意包捕获和实时企业数据。这些数据反馈对我们的帮助是巨大的,它能够引导我们的分析,并且发展出最具信息量的流动特征。我们所分析的数据特性是十分有趣的,为了让大家理解有趣在那里,我们首先关注一个特定的恶意软件样本,bestafera,它是著名的键盘记录和数据泄露软件。
本文来自无奈人生安全网
通过数据包长度和时间进行行为分析
图2显示了两个不同TLS会话的数据包长度和到达间隔:图2a中的谷歌搜索和图2b中的bestafera启动连接。 x轴表示时间,向上的线表示从客户端(源)发送到服务器(目的地)的数据包大小,向下的线表示从服务器发送到客户端的数据包大小。红线表示未加密的消息,黑线是加密的应用程序数据记录的大小。
谷歌搜索遵循一种典型模式:客户端的初始请求位于一个小的出站数据包中,然后是大量响应,它跨越许多MTU大小的数据包。这几个来回的数据包是谷歌在我还在输入时,自动完成的搜索。 最后,谷歌认为它对我输入的内容有自己想法,所以发送了一组更新的结果。 bestafera与之通信的服务器首先发送一个包含自签名证书的数据包,这可以看作是图2b中第一个向下的细红线。握手后,客户端立即开始将数据泄露到服务器。然后是暂停,服务器定期发送计划命令和控制消息。针对会话内容,数据包长度和到达时间间隔无法提供更深入的见解,但它们确实有助于推断会话的行为方面。
无奈人生安全网
使用TLS元数据对应用程序进行指纹识别
TLS ClientHello消息提供了两个特别有趣的信息,他们可以用来区分不同的TLS库和应用程序。客户端向服务器提供了一个列表,这其中包括在客户端的优先级中订购的合适密码套件的列表。每个密码套件定义了一组方法,例如加密算法和伪随机函数,这些方法将使用TLS建立连接和传输数据。客户端还可以发布一组TLS扩展,它可以向服务器提供密钥交换所需的参数,例如ec_point_formats。 www.wnhack.com
在提供的唯一密码套件的数量和提供的不同子组中,密码套件提供的向量是可以变化。类似的扩展列表也会根据连接的上下文而变化。因为大多数应用程序通常有不同的优先级,所以,在实践中,这些列表可以而且确实包含大量歧视性信息。例如,桌面浏览器倾向于更重的重量,更安全的加密算法,移动应用程序倾向于更高效的加密算法。他默认的密码套件提供与TLS库捆绑的客户向量,而且他通常提供更广泛的密码套件,这样可以帮助测试服务器配置。
大多数用户级应用程序,以及在野外看到的大量TLS连接,都使用流行的TLS库,如BoringSSL,NSS或OpenSSL。这些应用程序通常具有唯一的TLS指纹,因为开发人员会修改库的默认值,这样便能优化它的应用程序。更明确地说,OpenSSL 1.0.1r中s_client的TLS指纹很可能与使用OpenSSL 1.0.1r进行通信的应用程序不同。这也是为什么bestafera的TLS指纹既有趣又独特的原因——它使用OpenSSL 1.0.1r的默认设置来创建其TLS连接。
www.wnhack.com
应用机器学习
特征表示
对于本文,我们关注的是三种数据类型的简单特性:传统的NetFlow、数据包长度以及从TLS ClientHello获取的信息。这些数据类型都是从单个TLS会话中提取的,但我们还开发了包含多个流的特征模型。在训练之前,将所有特征都归一化为具有零均值和单位方差。
Legacy 本文来自无奈人生安全网
我们使用了传统NetFlow中存在的5个功能:流的持续时间、从客户端发送的数据包数、从服务器发送的数据包数、从客户端发送的字节数以及从服务器发送的字节数。
SPL
我们创建一个长度为20的特征向量,其中每个条目都是双向流中相应的数据包大小。从客户端到服务器的数据包大小是正数,从服务器到客户端的数据包大小是负数。
TLS 无奈人生安全网
我们分析了提供的密码套件列表,以及ClientHello消息中包含的广告扩展列表。在我们的数据中,我们观察到176个独特的密码套件和21个独特的扩展,这导致了长度为197的二进制特征向量。如果密码套件或扩展名出现在ClientHello消息中,则相应的功能设置为1。
学习
所有的结果都使用了scikit-learn随机森林实现。基于我们之前进行的纵向研究,我们将集合中树木的数量设置为125棵,并且将树的每一次分裂所考虑的特征数量设置为特征总数的平方根。随机森林模型使用的特性集由遗留特性、SPL、TLS特性的某些子集组成,具体需要看实验情况。。 (责任编辑:admin)
【声明】:无奈人生安全网(http://www.wnhack.com)登载此文出于传递更多信息之目的,并不代表本站赞同其观点和对其真实性负责,仅适于网络安全技术爱好者学习研究使用,学习中请遵循国家相关法律法规。如有问题请联系我们,联系邮箱472701013@qq.com,我们会在最短的时间内进行处理。