在Microsoft Edge中实现DOM树
DOM是Web平台编程模型的基础,其设计和性能直接影响着浏览器管道(Pipeline)的模型,然而,DOM的历史演化却远不是一个简单的事情。
在过去三年中,微软的安全专家们早已经开始在Microsoft Edge上对DOM进行了重构,这次重构的主要目标就是要搭建一个更加先进的架构,提供更好的实际操作性能和更加简洁的操作。在这篇文章中,微软的安全专家们将引导我们来了解Internet Explorer和Microsoft Edge中DOM的历史演变过程,以及他们在这几年对DOM树先进化演变的影响。现在我们已经能看到新的DOM架构对Windows 10 Creators Update性能大幅提升的帮助:
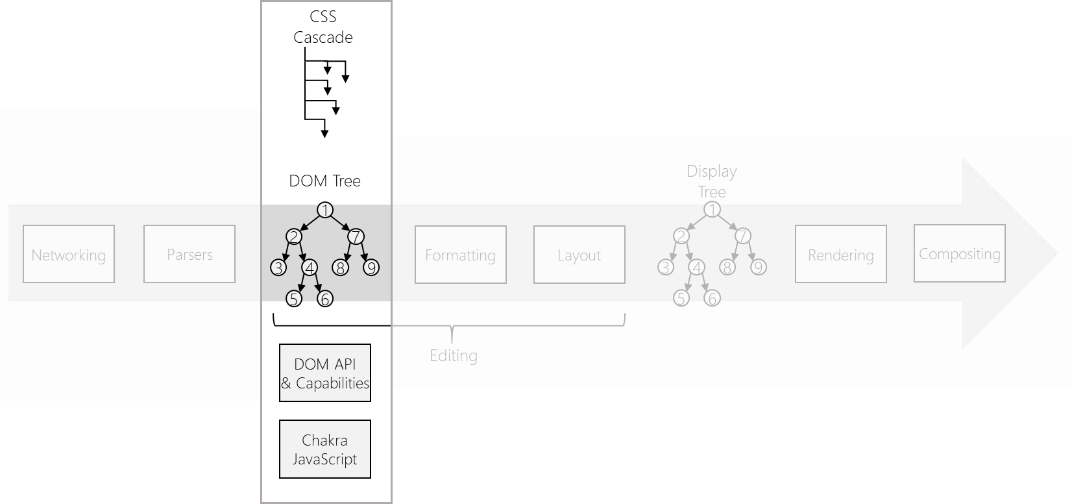
安全专家们认为真正的DOM架构应该是几个子系统的相互协调与合作,比如在Microsoft Edge中,就包括JS中的事件绑定,事件捕获,事件编辑,拼写检查,HTML属性,CSSOM,文本设置和其他所有相关的功能。在这些子系统中,DOM树正位于中心。
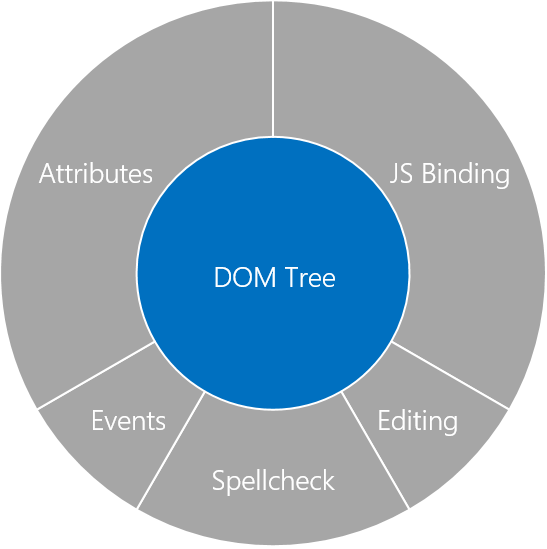
由上图可以看出,DOM真的是构成Web编程模型的几个子系统的协调。但这只是DOM非常表面的东西,真正的一些内部细节,还要从DOM的历史开始说起。
Internet Explorer DOM树的历史
如今的网络开发人员一提起DOM,就通常会想到一棵看起来像这样结构的树:
然而,现实操作却并不是像我们想的这么简单,比如,Internet Explorer的DOM实现就相当的复杂。
简单来说,Internet Explorer的DOM就是为了满足90年代的网页设计的,当时设计原始数据结构时,Web主要是一个文档查看器,顶多包含几个动画GIF和几幅图像。因此,DOM的算法和数据结构更接近于Microsoft Word这样的文档查看器。回想早期的网络,因为JavaScript不允许脚本化网页,所以我们所了解的DOM树根本就不存在。当是,由于文本是主要的实现手段,所以DOM的内部设计都是围绕快速,高效的文本来进行存储和操作的。WYSIWYG富文本编辑器就是当是的产物,专门用于字符插入和有限的格式化。
以文本为中心的设计
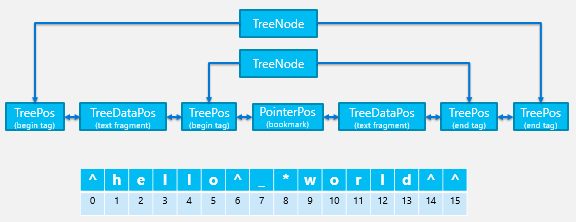
作为以文本为中心的设计结果,DOM的原理结构就是为文本存储做准备的,这是一个复杂的文本数组系统,可以通过最少或在没有内存分配的情况下进行高效拆分和连接。存储功能可以将文本和标签表示为线性进程,可由全局索引或字符位置(CP)寻址。在给定的CP中插入文本是非常高效的,并且通过高效的“拼接”操作集中复制或粘贴一系列文本。下图就清楚的表明如何将包含“hello world”的简单标记加载到文本存储中,以及如何为每个字符和标签分配CP。

为了存储非文本数据,例如,格式化和分组信息,另一组对象的存储就必须单独维护,比如,树位置(TreePos对象)的双向链接列表。 TreePos对象是HTML源标记中的标签语义,每个逻辑元素由开始和结束TreePos表示。这种线性结构使得在深度优先时,可以很快的遍历整个DOM树,几乎每个DOM都需要搜索API,CSS以及布局算法。之后,安全专家们将TreePos对象扩展到另外两种“位置”:TreeDataPos(用于指示文本的占位符)和PointerPos(用于指示插入符号,范围边界点,如生成的内容节点)。
每个TreePos对象还包括一个CP对象,它作为标签的全局序数索引(对于像legacy document.all API这样的东西有用)。从TreePos进入文本存储时要用到CP,通过比较节点顺序,甚至减去CP索引来查找文本的长度。
为了将这些节点整合在一起,TreeNode将会把它们绑定在一起,并建立了JavaScript DOM所期望的“树”的层次,如下所示。
增加复杂层次
原有的这些CP基础造成了DOM极其复杂,为了使整个系统能高效的运行,CP必须是最新的。因此,在每次DOM操作之后,例如输入文本,复制或粘贴,DOM API操作,甚至点击页面在DOM中设置插入点都可以更新CP。最初,DOM操作主要由HTML解析器或用户操作驱动,所以CP始终保持最新的模型是完全合理的。但是随着JavaScript和DHTML的兴起,这些操作变得越来越普遍和频繁。
为了保持原来的更新速度,DOM添加了新的结构并且伸展树(SplayTree)也随之产生,伸展树是在TreePos对象上添加了一系列重叠的树连接。首先这些复杂结构的增加提高了DOM的性能,可以用O(log n)速度实现全局CP更新。然而,伸展树实际上仅针对重复的本地搜索进行优化。
另一个在设计中出现的现象就是前面提到的复制或粘贴的“拼接”操作被扩展到处理所有的树突变中。核心的拼接功能分三步进行,如下图所示。
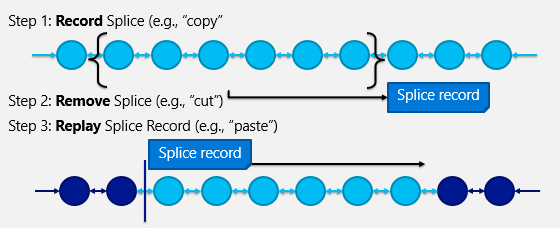
在步骤1中,拼接将通过从操作开始到操作结束遍历树形位置来记录拼接信息。然后创建一个拼接记录,其中包含此操作的命令指令。
在步骤2中,与该操作相关联的所有节点,即,TreeNode和TreePos对象会从树中删除。要注意的是,在IE DOM树中,TreeNode / TreePos对象与脚本引用的Element对象不同,以便于重叠标签,因此删除它们不是从功能方面考虑的。
在步骤3中,使用拼接记录来重新创建目标位置中的新对象。例如,为了完成一个appendChild DOM操作,splice创建了一个围绕节点的范围(从TreeNode开始到TreePos结尾),将原来位置的编辑范围经过拼接,创建了新的节点来表示节点及其子节点的新位置。大家可以想象一下,这样一来虽然创造了很多内存分配,但算法的速度也降低了很多。
DOM是Web平台编程模型的基础,其设计和性能直接影响着浏览器管道(Pipeline)的模型,然而,DOM的历史演化却远不是一个简单的事情。
在过去三年中,微软的安全专家们早已经开始在Microsoft Edge上对DOM进行了重构,这次重构的主要目标就是要搭建一个更加先进的架构,提供更好的实际操作性能和更加简洁的操作。在这篇文章中,微软的安全专家们将引导我们来了解Internet Explorer和Microsoft Edge中DOM的历史演变过程,以及他们在这几年对DOM树先进化演变的影响。现在我们已经能看到新的DOM架构对Windows 10 Creators Update性能大幅提升的帮助:
安全专家们认为真正的DOM架构应该是几个子系统的相互协调与合作,比如在Microsoft Edge中,就包括JS中的事件绑定,事件捕获,事件编辑,拼写检查,HTML属性,CSSOM,文本设置和其他所有相关的功能。在这些子系统中,DOM树正位于中心。
www.wnhack.com
由上图可以看出,DOM真的是构成Web编程模型的几个子系统的协调。但这只是DOM非常表面的东西,真正的一些内部细节,还要从DOM的历史开始说起。
Internet Explorer DOM树的历史
如今的网络开发人员一提起DOM,就通常会想到一棵看起来像这样结构的树:
然而,现实操作却并不是像我们想的这么简单,比如,Internet Explorer的DOM实现就相当的复杂。
简单来说,Internet Explorer的DOM就是为了满足90年代的网页设计的,当时设计原始数据结构时,Web主要是一个文档查看器,顶多包含几个动画GIF和几幅图像。因此,DOM的算法和数据结构更接近于Microsoft Word这样的文档查看器。回想早期的网络,因为JavaScript不允许脚本化网页,所以我们所了解的DOM树根本就不存在。当是,由于文本是主要的实现手段,所以DOM的内部设计都是围绕快速,高效的文本来进行存储和操作的。WYSIWYG富文本编辑器就是当是的产物,专门用于字符插入和有限的格式化。
以文本为中心的设计
作为以文本为中心的设计结果,DOM的原理结构就是为文本存储做准备的,这是一个复杂的文本数组系统,可以通过最少或在没有内存分配的情况下进行高效拆分和连接。存储功能可以将文本和标签表示为线性进程,可由全局索引或字符位置(CP)寻址。在给定的CP中插入文本是非常高效的,并且通过高效的“拼接”操作集中复制或粘贴一系列文本。下图就清楚的表明如何将包含“hello world”的简单标记加载到文本存储中,以及如何为每个字符和标签分配CP。 copyright 无奈人生
为了存储非文本数据,例如,格式化和分组信息,另一组对象的存储就必须单独维护,比如,树位置(TreePos对象)的双向链接列表。 TreePos对象是HTML源标记中的标签语义,每个逻辑元素由开始和结束TreePos表示。这种线性结构使得在深度优先时,可以很快的遍历整个DOM树,几乎每个DOM都需要搜索API,CSS以及布局算法。之后,安全专家们将TreePos对象扩展到另外两种“位置”:TreeDataPos(用于指示文本的占位符)和PointerPos(用于指示插入符号,范围边界点,如生成的内容节点)。
每个TreePos对象还包括一个CP对象,它作为标签的全局序数索引(对于像legacy document.all API这样的东西有用)。从TreePos进入文本存储时要用到CP,通过比较节点顺序,甚至减去CP索引来查找文本的长度。
为了将这些节点整合在一起,TreeNode将会把它们绑定在一起,并建立了JavaScript DOM所期望的“树”的层次,如下所示。
www.wnhack.com 增加复杂层次
原有的这些CP基础造成了DOM极其复杂,为了使整个系统能高效的运行,CP必须是最新的。因此,在每次DOM操作之后,例如输入文本,复制或粘贴,DOM API操作,甚至点击页面在DOM中设置插入点都可以更新CP。最初,DOM操作主要由HTML解析器或用户操作驱动,所以CP始终保持最新的模型是完全合理的。但是随着JavaScript和DHTML的兴起,这些操作变得越来越普遍和频繁。
为了保持原来的更新速度,DOM添加了新的结构并且伸展树(SplayTree)也随之产生,伸展树是在TreePos对象上添加了一系列重叠的树连接。首先这些复杂结构的增加提高了DOM的性能,可以用O(log n)速度实现全局CP更新。然而,伸展树实际上仅针对重复的本地搜索进行优化。
另一个在设计中出现的现象就是前面提到的复制或粘贴的“拼接”操作被扩展到处理所有的树突变中。核心的拼接功能分三步进行,如下图所示。
在步骤1中,拼接将通过从操作开始到操作结束遍历树形位置来记录拼接信息。然后创建一个拼接记录,其中包含此操作的命令指令。
在步骤2中,与该操作相关联的所有节点,即,TreeNode和TreePos对象会从树中删除。要注意的是,在IE DOM树中,TreeNode / TreePos对象与脚本引用的Element对象不同,以便于重叠标签,因此删除它们不是从功能方面考虑的。
在步骤3中,使用拼接记录来重新创建目标位置中的新对象。例如,为了完成一个appendChild DOM操作,splice创建了一个围绕节点的范围(从TreeNode开始到TreePos结尾),将原来位置的编辑范围经过拼接,创建了新的节点来表示节点及其子节点的新位置。大家可以想象一下,这样一来虽然创造了很多内存分配,但算法的速度也降低了很多。
www.wnhack.com