又出新玩法?微软公式编辑器系列漏洞新利用方式
此前,微软发布的月度安全更新中修复了多个最新的Office漏洞(CVE-2017-11882,CVE-2018-0798 和CVE-2018-0802)。该漏洞为Office公式编辑器的最新漏洞,微软对此的处理方式是将该模块删掉。
然而即使模块在最新版本中被删掉,仍然有大量攻击者在利用CVE-2017-11882+CVE-2018-0802的漏洞文档进行攻击。
而就在3月18日,金睛安全研究团队捕获到一些奇怪的RTF样本。这批样本相比较CVE-2018-0802传统利用方式而言,采用了一种新的利用方式,能够绕过市面上大多数杀软,并且即使部分杀软能查杀,也无法正确识别漏洞。
下图为VT报警信息。

技术细节
首先,经过分析,我们发现这批样本有一个通用特征:都内嵌了一个CFBF(Compound File Binary Format)对象,将该文件提取后发现只有一个“\x01Ole10Native”流。

在文本编辑器中浏览该文件也未发现明文的URL,文件路径或是命令等信息。

经过分析,我们发现这批样本是公式编辑器系列漏洞的新利用方式。可以用于构造和CVE-2017-11882,CVE-2018-0802相同触发机制,但静态特征更少的恶意样本。
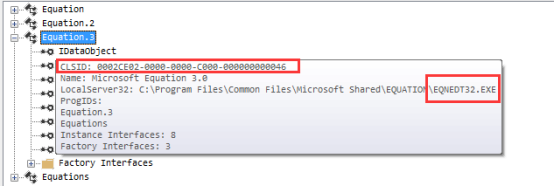
首先可以观察到,这个CFBF对象的Root Entry带有一个CLSID {0002CE02-0000-0000-C000-000000000046}。

而这个CLSID对应的对象是Microsoft Equation 3.0,即该对象是一个公式3.0编辑器对象。
而在[MS-OLEDS]中可以查到“\x01Ole10Native”流的结构。前四个字节表示数据长度,后面的字节流均为对应的数据。但是可以发现,这段数据的含义并不显然。也许是shellcode,但是shellcode的头部并不在偏移量为0的位置。
我们来回顾一下之前在CVE-2017-11882中,公式数据被加载和读取的过程。
通过Unicode字符串”Equation Native”可以定位到数据流加载的过程。如下图所示。

注意到这里可能是对虚函数表的调用,28行的s_EquationNative是流名,则v10这个唯一的out变量应该对应于IStream,那么a2应该对应于IStorage。
进行标注后得到以下结果。

我们来梳理一下图中这一段的逻辑。
在第26~29行,公式编辑器首先尝试从CFBF对象中读取名为”Equation Native”的流。如果失败(v11不为0),则尝试读取名为“\x01Ole10Native”的流。
在第35行,公式编辑器根据流的类型,从流中读取不同大小的数据到一个变量中。如果流的类型是“Equation Native”,则读取0x1C个字节;如果流的类型是“\x01Ole10Native”,则读取4个字节。根据之前对于CVE-2017-11882等漏洞的分析,可以得知这里是在处理公式对象的OLE头。
在第38行,判断了数据的头部是否正确。如果流的类型是“\x01Ole10Native”,则不作任何检查;如果流的类型是“Equation Native”,则判断OLE头的前两个字节是不是0x001C(小端序),及随后的四个字节是不是0×00020000(小端序)。
在第40~43行,根据流的类型为接下来的公式数据分配内存空间。如果流的类型是“\x01Ole10Native”,则流的前4个字节([v9+0])就是数据大小;如果流的类型是“Equation Native”,则流的第8个字节处的DWORD就是数据大小,而图中的v14([esp+0x3C])正好是v13([esp+0x34])偏移量为8的位置。
在第50~53行,根据流的类型来读入公式数据。对两种流的处理实际是相同的。而在第66行的函数调用中,程序对读入的公式数据开始进行处理。
也就是说,两种不同的流,对应的数据,区别仅仅是数据头:“Equation Native“流的数据头是0x1C个字节,而”\x01Ole10Native”流的数据头仅仅是4个字节。
我们继续回到样本数据处进行查看。

前面的5个字节是公式头数据。按理说应该是如下格式。
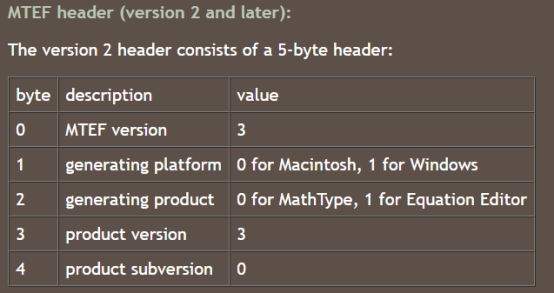
但是实际上,上图中的第1、3、4三个字段是被公式编辑器的处理函数忽略掉了的。

此前,微软发布的月度安全更新中修复了多个最新的Office漏洞(CVE-2017-11882,CVE-2018-0798 和CVE-2018-0802)。该漏洞为Office公式编辑器的最新漏洞,微软对此的处理方式是将该模块删掉。
然而即使模块在最新版本中被删掉,仍然有大量攻击者在利用CVE-2017-11882+CVE-2018-0802的漏洞文档进行攻击。
而就在3月18日,金睛安全研究团队捕获到一些奇怪的RTF样本。这批样本相比较CVE-2018-0802传统利用方式而言,采用了一种新的利用方式,能够绕过市面上大多数杀软,并且即使部分杀软能查杀,也无法正确识别漏洞。
下图为VT报警信息。
技术细节
首先,经过分析,我们发现这批样本有一个通用特征:都内嵌了一个CFBF(Compound File Binary Format)对象,将该文件提取后发现只有一个“\x01Ole10Native”流。
在文本编辑器中浏览该文件也未发现明文的URL,文件路径或是命令等信息。
经过分析,我们发现这批样本是公式编辑器系列漏洞的新利用方式。可以用于构造和CVE-2017-11882,CVE-2018-0802相同触发机制,但静态特征更少的恶意样本。
首先可以观察到,这个CFBF对象的Root Entry带有一个CLSID {0002CE02-0000-0000-C000-000000000046}。
而这个CLSID对应的对象是Microsoft Equation 3.0,即该对象是一个公式3.0编辑器对象。
而在[MS-OLEDS]中可以查到“\x01Ole10Native”流的结构。前四个字节表示数据长度,后面的字节流均为对应的数据。但是可以发现,这段数据的含义并不显然。也许是shellcode,但是shellcode的头部并不在偏移量为0的位置。
copyright 无奈人生
我们来回顾一下之前在CVE-2017-11882中,公式数据被加载和读取的过程。
通过Unicode字符串”Equation Native”可以定位到数据流加载的过程。如下图所示。
注意到这里可能是对虚函数表的调用,28行的s_EquationNative是流名,则v10这个唯一的out变量应该对应于IStream,那么a2应该对应于IStorage。
进行标注后得到以下结果。
我们来梳理一下图中这一段的逻辑。
在第26~29行,公式编辑器首先尝试从CFBF对象中读取名为”Equation Native”的流。如果失败(v11不为0),则尝试读取名为“\x01Ole10Native”的流。
在第35行,公式编辑器根据流的类型,从流中读取不同大小的数据到一个变量中。如果流的类型是“Equation Native”,则读取0x1C个字节;如果流的类型是“\x01Ole10Native”,则读取4个字节。根据之前对于CVE-2017-11882等漏洞的分析,可以得知这里是在处理公式对象的OLE头。
在第38行,判断了数据的头部是否正确。如果流的类型是“\x01Ole10Native”,则不作任何检查;如果流的类型是“Equation Native”,则判断OLE头的前两个字节是不是0x001C(小端序),及随后的四个字节是不是0×00020000(小端序)。
在第40~43行,根据流的类型为接下来的公式数据分配内存空间。如果流的类型是“\x01Ole10Native”,则流的前4个字节([v9+0])就是数据大小;如果流的类型是“Equation Native”,则流的第8个字节处的DWORD就是数据大小,而图中的v14([esp+0x3C])正好是v13([esp+0x34])偏移量为8的位置。
在第50~53行,根据流的类型来读入公式数据。对两种流的处理实际是相同的。而在第66行的函数调用中,程序对读入的公式数据开始进行处理。
也就是说,两种不同的流,对应的数据,区别仅仅是数据头:“Equation Native“流的数据头是0x1C个字节,而”\x01Ole10Native”流的数据头仅仅是4个字节。
我们继续回到样本数据处进行查看。
本文来自无奈人生安全网 前面的5个字节是公式头数据。按理说应该是如下格式。
但是实际上,上图中的第1、3、4三个字段是被公式编辑器的处理函数忽略掉了的。
内容来自无奈安全网