子域名接管:二阶漏洞利用
最近,我在琢磨着扩展一下我的自动漏洞挖掘引擎。我的第一个想法就是将二阶漏洞加入到我的子域名接管扫描过程中。在本文中,我会讲解我是如何解决这个问题的,并且如何更加高效的完成这个自动化的扫描过程。关于这个主题,其实有一篇文章已经讲的很不错了,文章链接在这里,但我觉得还有些东西需要补充一下。
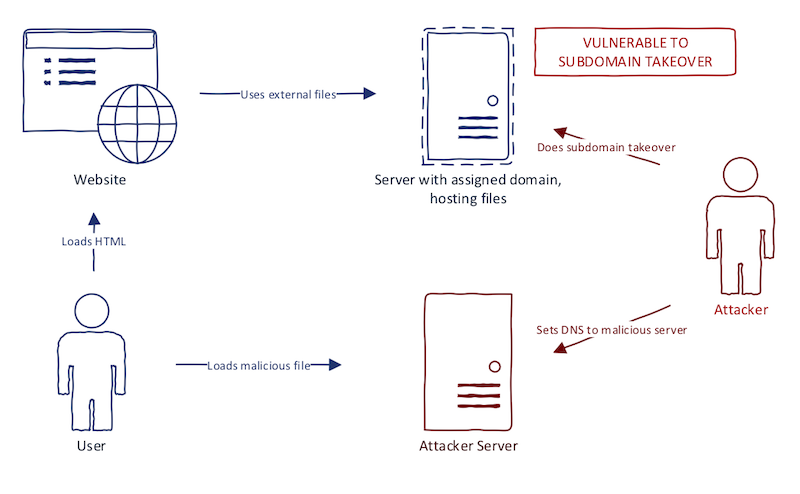
当网站在错误的地方使用“可接受的域名”时,就容易出现子域名二次利用漏洞。假如网站引用了外部域的JavaScript文件,当这个域名存在子域名接管漏洞时会发生什么?当JavaScript文件不可用时(比如域已经过期),这时浏览器就会加载失败,而且不易察觉。如果不是因为该JavaScript文件对网站功能极其重要(比如实时聊天功能)的话,管理员可能都注意不到网站的行为有什么异常。我们可以注册这个域名,并且放上我们自己的JavaScript文件,写入一个xss payload。这是一个经典的子域名接管案例,我在之前的文章中已经分析过了,文章链接在这里。下图解释了这个xss流程:
为什么叫做二阶漏洞呢?首先我们得知道一阶子域名漏洞的定义,一阶漏洞就是只针对目标应用程序子域所存在的子域名接管漏洞。而二阶漏洞的定义其实就是扩展了域的范围,对除了目标应用程序子域外,能够产生重大影响的域。
对于子域二阶漏洞的利用,网上至少有一个开源的利用工具:second-order。这个工具的问题是它没有检查本文所描述的所有范围。正因如此,所以这对于我想扩展它的功能来说是一个很好的开头,不过,我多少有点不自信,因为这个工具是用go语言写的。
二阶漏洞并不局限于JavaScript文件。我们也可以把这种方法应用到CORS漏洞上。建议大家去hackerone看下这篇报告,文章讲的内容正是我提到的。基本的思想就是:我们需要从某些位置提取链接和域,这些位置发生了子域名接管的话会导致严重的问题。那么这些位置具体在哪儿呢?如下:
· script标签—影响:XSS
· a 标签—影响:社工
· link标签—影响:点击劫持
· CORS响应头—影响:数据泄露
实现
现在我们来看看如何使用Python来实现它。实现过程如下图:

第一部分是由爬虫组成。爬虫的技术细节我就不多讲了。至于使用什么方案就看你自己了。有如下几种方案你可以选择:
· 仅请求找到的每个子域
· 进行有限的爬行(比如高度为1的BFS树)
· 进行完全爬行
任何这些爬虫产生的HTML文件都会进入到提取主机中(不过第一选择绝对不是爬行)。
提取过程需要几步来完成。我使用一个函数来处理每一步。我们现在再来深入地看一下这个Python脚本:
from bs4 import BeautifulSoup
def extract_javascript(domain, source_code):
'''
Extract and normalize external javascript files from HTML
'''
tree = BeautifulSoup(source_code, 'html.parser')
scripts = [normalize_url(domain, s.get('src')) for s in tree.find_all('script') if s.get('src')]
return list(set(scripts))
这段代码会从HTML文件中的script标签里提取所有链接。我使用了BeautifulSoup这个模块来解析HTML。仔细看看代码的话,你会发现有一个未知的函数normalize_url。我很快就会解释这个函数:
def extract_links(domain, source_code):
'''
Extract and normalize links in HTML file
'''
tree = BeautifulSoup(source_code, 'html.parser')
hrefs = [normalize_url(domain, s.get('href')) for s in tree.find_all('a') if s.get('href')]
return list(set(hrefs))
def extract_styles(domain, source_code):
'''
Extract and normalize CSS in HTML file
'''
tree = BeautifulSoup(source_code, 'html.parser')
hrefs = [normalize_url(domain, s.get('href')) for s in tree.find_all('link') if s.get('href')]
return list(set(hrefs))
不要感到奇怪,我们这里是在对类似于script的标签进行提取。
import requests
def extract_cors(url):
r = requests.get(url, timeout=5)
if not r.headers.get('Access-Control-Allow-Origin'):
return
cors = r.headers['Access-Control-Allow-Origin'].split(',')
if '*' in cors:
# Use your imagination here
return []
return cors
这个脚本有些不同的地方,不过也不难理解。不过,表达多个来源域有很多不同的方法。我觉得可以用“;”作为分隔符。你可以自己进行研究,让它变得更加可靠。提供多个来源域的方法也会有所不同。
最近,我在琢磨着扩展一下我的自动漏洞挖掘引擎。我的第一个想法就是将二阶漏洞加入到我的子域名接管扫描过程中。在本文中,我会讲解我是如何解决这个问题的,并且如何更加高效的完成这个自动化的扫描过程。关于这个主题,其实有一篇文章已经讲的很不错了,文章链接在这里,但我觉得还有些东西需要补充一下。
当网站在错误的地方使用“可接受的域名”时,就容易出现子域名二次利用漏洞。假如网站引用了外部域的JavaScript文件,当这个域名存在子域名接管漏洞时会发生什么?当JavaScript文件不可用时(比如域已经过期),这时浏览器就会加载失败,而且不易察觉。如果不是因为该JavaScript文件对网站功能极其重要(比如实时聊天功能)的话,管理员可能都注意不到网站的行为有什么异常。我们可以注册这个域名,并且放上我们自己的JavaScript文件,写入一个xss payload。这是一个经典的子域名接管案例,我在之前的文章中已经分析过了,文章链接在这里。下图解释了这个xss流程:
本文来自无奈人生安全网
为什么叫做二阶漏洞呢?首先我们得知道一阶子域名漏洞的定义,一阶漏洞就是只针对目标应用程序子域所存在的子域名接管漏洞。而二阶漏洞的定义其实就是扩展了域的范围,对除了目标应用程序子域外,能够产生重大影响的域。
对于子域二阶漏洞的利用,网上至少有一个开源的利用工具:second-order。这个工具的问题是它没有检查本文所描述的所有范围。正因如此,所以这对于我想扩展它的功能来说是一个很好的开头,不过,我多少有点不自信,因为这个工具是用go语言写的。
二阶漏洞并不局限于JavaScript文件。我们也可以把这种方法应用到CORS漏洞上。建议大家去hackerone看下这篇报告,文章讲的内容正是我提到的。基本的思想就是:我们需要从某些位置提取链接和域,这些位置发生了子域名接管的话会导致严重的问题。那么这些位置具体在哪儿呢?如下:
· script标签—影响:XSS
· a 标签—影响:社工
· link标签—影响:点击劫持
· CORS响应头—影响:数据泄露
实现
现在我们来看看如何使用Python来实现它。实现过程如下图:
第一部分是由爬虫组成。爬虫的技术细节我就不多讲了。至于使用什么方案就看你自己了。有如下几种方案你可以选择:
· 仅请求找到的每个子域
· 进行有限的爬行(比如高度为1的BFS树)
· 进行完全爬行
任何这些爬虫产生的HTML文件都会进入到提取主机中(不过第一选择绝对不是爬行)。
提取过程需要几步来完成。我使用一个函数来处理每一步。我们现在再来深入地看一下这个Python脚本:
from bs4 import BeautifulSoup
def extract_javascript(domain, source_code):
'''
Extract and normalize external javascript files from HTML
'''
www.wnhack.com
tree = BeautifulSoup(source_code, 'html.parser')
scripts = [normalize_url(domain, s.get('src')) for s in tree.find_all('script') if s.get('src')]
return list(set(scripts))
这段代码会从HTML文件中的script标签里提取所有链接。我使用了BeautifulSoup这个模块来解析HTML。仔细看看代码的话,你会发现有一个未知的函数normalize_url。我很快就会解释这个函数:
def extract_links(domain, source_code):
'''
Extract and normalize links in HTML file
'''
tree = BeautifulSoup(source_code, 'html.parser')
hrefs = [normalize_url(domain, s.get('href')) for s in tree.find_all('a') if s.get('href')]
return list(set(hrefs))
def extract_styles(domain, source_code):
'''
Extract and normalize CSS in HTML file
'''
tree = BeautifulSoup(source_code, 'html.parser')
hrefs = [normalize_url(domain, s.get('href')) for s in tree.find_all('link') if s.get('href')]
return list(set(hrefs))
不要感到奇怪,我们这里是在对类似于script的标签进行提取。
import requests
def extract_cors(url):
r = requests.get(url, timeout=5)
if not r.headers.get('Access-Control-Allow-Origin'):
return
cors = r.headers['Access-Control-Allow-Origin'].split(',')
if '*' in cors:
# Use your imagination here
return []
return cors
这个脚本有些不同的地方,不过也不难理解。不过,表达多个来源域有很多不同的方法。我觉得可以用“;”作为分隔符。你可以自己进行研究,让它变得更加可靠。提供多个来源域的方法也会有所不同。
copyright 无奈人生
本文来自无奈人生安全网
内容来自无奈安全网